
Hardware Overview
The NVIDIA MGX™ architecture offers a new standard for modular server design, providing scalable and adaptable solutions for AI and high-performance computing. This allows system manufacturers to efficiently meet evolving technological demands, ensuring compatibility with NVIDIA's range of products. Incorporating the NVIDIA® Grace™ Hopper™ Superchip boosts this platform by integrating powerful CPU and GPU functions into a single chip, optimizing data processing and enhancing performance for complex applications.
The AceleMax® AXG-AR211 is the first server to introduce the NVIDIA® Grace™ Hopper™ Superchip in conjunction with NVIDIA MGX™ architecture. This 2U server offers features particularly appealing to the AI/ML community.
The AceleMax® AXG-AR211

Key Features
- Grace Hopper Superchip
- Includes an H100 Tensor Core GPU with 96GB HBM3 memory and a Grace CPU.
- Note: A typical H100 GPU, PCIe or SXM5, has 80G HBM3 memory.
- NVIDIA Grace CPU
- Features 72 Arm Neoverse V2 cores.
- Note: This is not a typical X86 CPU which means GPU drivers need to be ARM64 based
- The Arm Neoverse V2 CPU is designed for cloud computing, high performance computing (HPC), and machine learning (ML) performance leadership. Neoverse V2 delivers up to twice the performance as Neoverse V1 and is the first V-series CPU with Armv9 performance, power, and security enhancements. For more information on Neoverse V2.
- 480G LPDDR5X System Memory
- LPDDR5X, or Low Power Double Data Rate 5X, supports data rates up to 8.533 Gbps, a 33% boost from the previous generation - LPDDR5 which supports a max of 6.4 Gbps. For more information on LPDDR5X.
- Additional PCIe Slots
- 3x FHFL PCIe 5.0 x16 slots in the back via riser
- Max TDP
- 1000W with air cooling
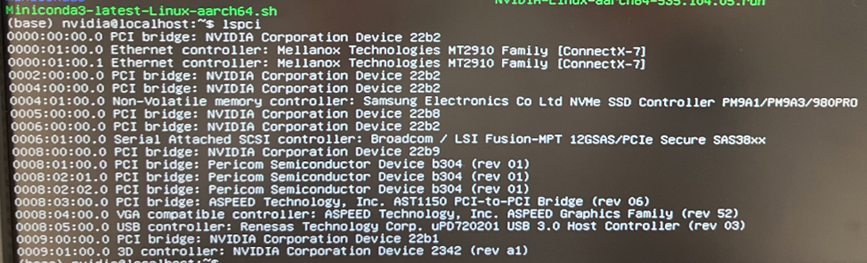
System Access
The system comes with login protection for the following access:
- BMC
- BIOS
For assistance with obtaining login credentials, please contact your server manufacturer or provider.
OS Installation
NVIDIA Base OS
NVIDIA provides the Ubuntu-based NVIDIA Base OS for the system. NVIDIA Base OS implements a stable and fully qualified operating systems for running AI, machine learning, and analytics applications on the DGX and MGX platforms.
For expert guidance on installation and support for the NVIDIA Base OS, our AMAX specialists are here to assist. For detailed installation instructions, please contact your server manufacturer or provider.
System Access
There is a default login included for the NVIDIA Base OS. For assistance with obtaining login credentials, please contact your server manufacturer or provider.
GPU Driver Update
ARM64 NVIDIA GPU Driver
When you login to the system for the first time and run a command such as nvidia-smi, you may see "No devices were found." This is expected as you need to manually update the GPU driver.
Steps to Update the ARM64 NVIDIA GPU Driver:
- Download the latest NVIDIA GPU Driver for the ARM architecture here.
- Unload default NVIDIA modules.
sudo rmmod nvidia-uvmsudo rmmod nvidia-drmsudo rmmod nvidia-modesetsudo rmmod nvidia
- Please verify before you proceed.
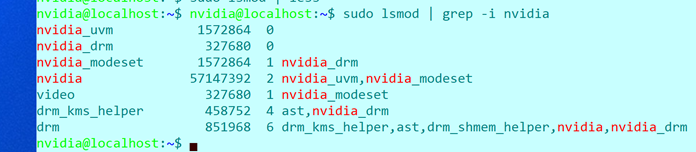
- Uninstall default NVIDIA GPU driver that is outdated.
sudo apt remove nvidia-driver-535-serversudo apt autoremove
- Execute run file with
-m=kernel-openoption.sudo ./NVIDIA-Linux-aarch64-535.104.05.run -m=kernel-open
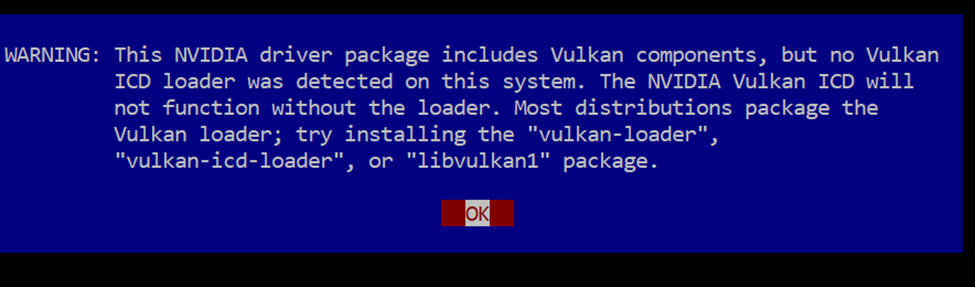
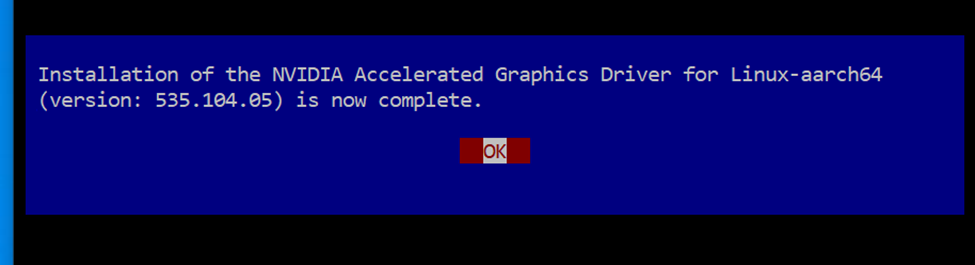
- You may see the following windows during the installation process:

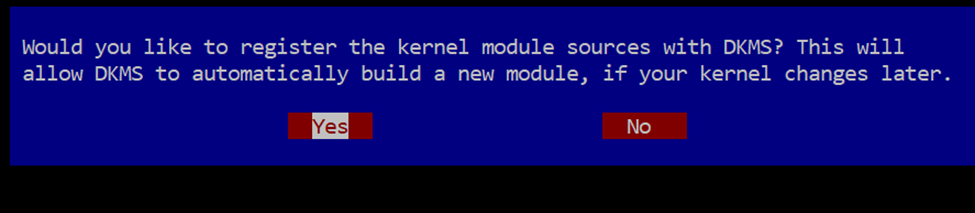
6. Reboot the system.
sudo nvidia-persistencedsudo reboot
7. Verify after the reboot.
sudo nvidia-smi -q
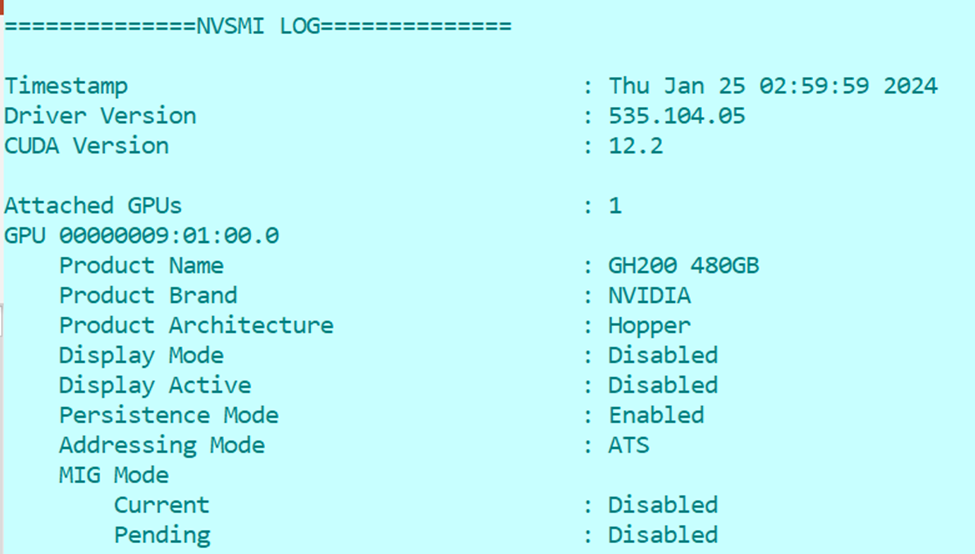
==============NVSMI LOG==============
Timestamp : Thu Jan 25 02:59:59 2024
Driver Version : 535.104.05
CUDA Version : 12.2
Attached GPUs : 1
GPU 00000009:01:00.0
Product Name : GH200 480GB
Product Brand : NVIDIA
Product Architecture : Hopper
Display Mode : Disabled
Display Active : Disabled
Persistence Mode : Enabled
Addressing Mode : ATS
MIG Mode
Current : Disabled
Pending : Disabled
CUDA Runtime Setup
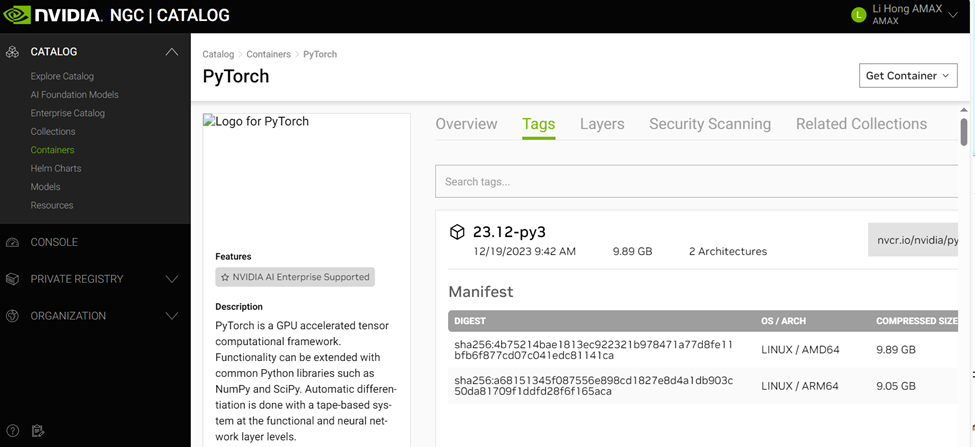
NVIDIA NGC PyTorch Container
Using the PyTorch container (latest v23.12-py3) from the NVIDIA NGC site is recommended. This container has built-in ARM64 and x86 support and does not require a login. You can find the container on the NVIDIA NGC site.
How to Pull Pytorch Container Supporting ARM
sudo docker pull nvcr.io/nvidia/pytorch:23.12-py3
Prerequisite Packages
- Install docker.
sudo apt install docker.io
- Install NVIDIA container toolkit.
- Install cuda-12.3 & latest driver v545.
Run the Container and Gain Terminal Access
sudo docker run --gpus all -p 8501:8080 --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -it --rm -v /path/to/your/code:/workspace/code nvcr.io/nvidia/pytorch:23.12-py3-p 8501:8080is optional if you need to run the application inside the container and provide access from your laptop for example. It will map the container port 8501 (used by Streamlit) to port 8080 of the system so that you can access via your browser by visitinghttp://GH200-IP-Address:8080-v /path/to/your/code:/workspace/codewill map your local path to be accessed at/workspace/codeinside the pytorch container.
sudo docker ps- You can find the image id of such pytorch container
sudo docker exec -it [container_id_or_name] /bin/bash- You can gain terminal access to the container and install any 3rd party libraries such as transformers etc.
Potential Error Messages
If you don’t have the NVIDIA container toolkit or CUDA installed correctly, you may see the following error message (side note – does OCI stand for Oracle Cloud Infrastructure here? If so, does it mean such PyTorch container is compiled by OCI team?)
$ sudo docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 nvcr.io/nvidia/pytorch:23.12-py3
docker: Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running hook #0: error running hook: exit status 1, stdout: , stderr: Auto-detected mode as 'legacy'
nvidia-container-cli: initialization error: load library failed: libnvidia-ml.so.1: cannot open shared object file: no such file or directory: unknown.
ERRO[0000] error waiting for container:
Deploy NVIDIA MGX with AMAX
If you're planning to upgrade to the latest NVIDIA MGX architecture and Grace Hopper Superchip but are concerned about the complexities of installation and system integration, AMAX is ready to assist. Our expertise extends beyond basic installation to encompass comprehensive data center solutions, including layout design, cluster architecture, network topology design, system bring-up, and performance tuning.

AceleMax® AXG-AR211
- Powered by NVIDIA® Grace™ Hopper™ Superchip, offering coherent memory between CPU and GPU through NVLink®- C2C interconnect
- Optimized for memory-intensive inference and high-performance computing (HPC) applications
- Supports up to 480GB LPDDRX embedded memory and 96GB HBM3 GPU memory
- Includes a 1+1 high-efficiency, hot-plug 2000W power supply unit with 80 Plus Titanium certification
We also specialize in both liquid and air-cooled facility retrofits and provide co-location services for site hosting. Partnering with AMAX gives you access to top-tier infrastructure solutions vital for advanced AI deployments. Contact us today to ensure your hardware is expertly integrated and optimized to meet your specific operational needs.