

When developing cutting edge AI or training Large Language Models (LLMs) billions of parameters in size, every component of hardware becomes crucial. A bottlenecked server can slow down the training process by hours or even days. At an enterprise level, a few minutes of server downtime can result in millions of dollars in lost revenue. At AMAX, we understand that ensuring optimal system performance is critical, down to the smallest component detail. Our extensive Quality Control (QC) process rigorously stress tests hardware, so even the slightest system defect can be detected in our lab instead of your production environment.
Surfacing Failure with NVIDIA HGX
Our commitment to quality and reliability was recently highlighted during a custom build of a GPU cluster featuring the ultra-powerful NVIDIA HGX™ H100 GPUs, NVIDIA 400G InfiniBand fabric, and 4th Gen AMD EPYC™ Series Processors. During our thorough advanced testing regimen, our team of engineers encountered an unexpected challenge – the GPUs were showing unexpected PCIe bandwidth drops across all systems up to a peak level of 76%. Recognizing the importance of maximum output in AI-driven applications, we had to discover the cause of this failure and resolve it before the system’s final deployment.
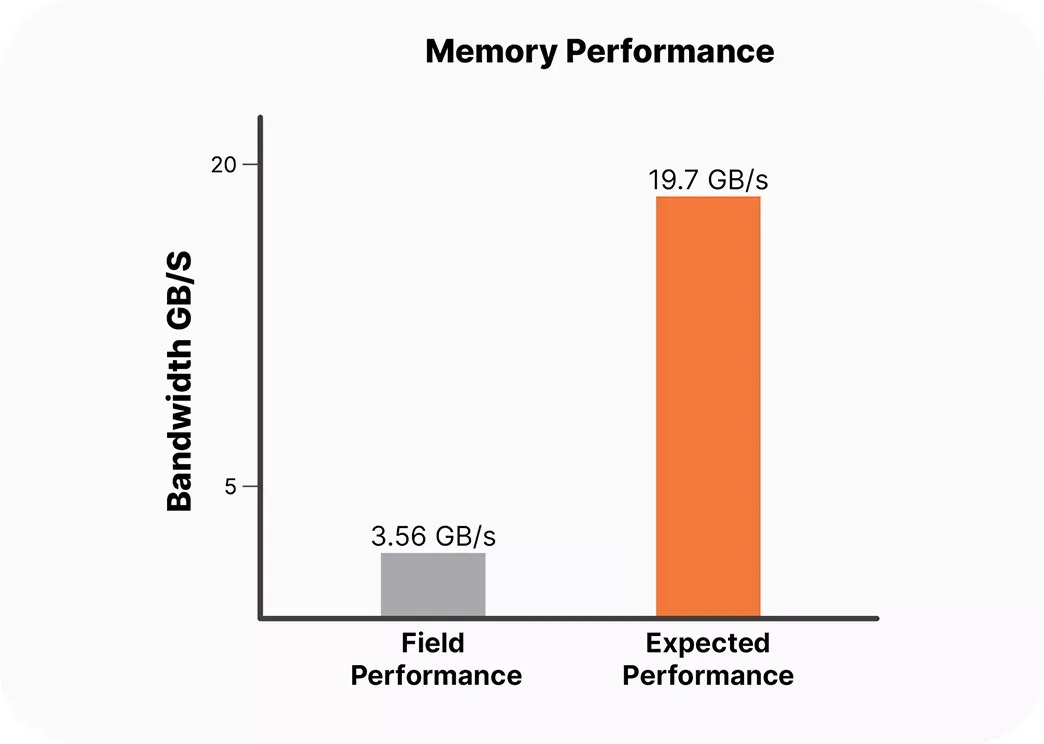
After running additional tests and sampling alternative cards, our team saw this challenge as an opportunity for proactive engagement. We immediately reached out to our Original Design Manufacturers (ODM) partners: Asus, Gigabyte, Supermicro, and Tyan, to raise awareness of the issue. After further discussion and providing ample evidence of the performance inconsistencies, we discovered that both the NVIDIA H100 and the NVIDIA RTX™ 6000 Ada Generation PCIe GPU were having similar issues when paired with the 4th Gen AMD EPYC Series Processor. Through our collaboration with the ODMs it was discovered that a BIOS defect was the cause of the bandwidth discrepancies. After running a BIOS update, our engineers tested the GPUs further, and concluded that the cause of the bandwidth drops had been fully resolved, restoring the cluster to its full capacity.
At AMAX, this case study stands as a testament to our unwavering commitment to quality. Although the cluster was operational from boot, its performance was not consistent with our standards. We were the first HGX POD provider to discover such an issue and raise awareness to our ODM partners. Our ability to identify, address, and overcome challenges underscores our dedication to providing our customers with the most robust, high-performance computing solutions. As we continue to push the boundaries of what’s possible in AI and High-Performance computing, you can trust that AMAX is at the forefront, delivering solutions that consistently meet and exceed your expectations.