

As artificial intelligence continues to transform industries, the deployment of large language models becomes crucial for meeting a wide array of inference requirements. For organizations, the key to unlocking these models' full potential lies in leveraging AI inference accelerators that offer superior throughput with minimal TCO, especially when scaled across extensive user bases. The NVIDIA H200 Tensor Core GPU showcases a pivotal advancement, doubling the inference performance of its predecessor, the H100, in processing complex models like Llama2 70B. This breakthrough not only enhances computational efficiencies but also sets new benchmarks for AI-driven endeavors.
NVIDIA H200 Overview
The NVIDIA H200, heralding a new era in GPU technology, is engineered to significantly elevate AI and HPC workloads with unparalleled performance and memory capabilities.

Featuring 141GB of HBM3e memory and a 4.8TB/s memory bandwidth, the H200, built on the NVIDIA Hopper architecture, marks a substantial leap over its predecessor, the H100, enhancing generative AI and scientific computing while improving energy efficiency and lowering ownership costs.
Projected Performance
This GPU is poised to redefine performance standards, doubling the inference performance of the H100 for large language models such as Llama2 70B, promising a transformative impact on AI model training and inference tasks.
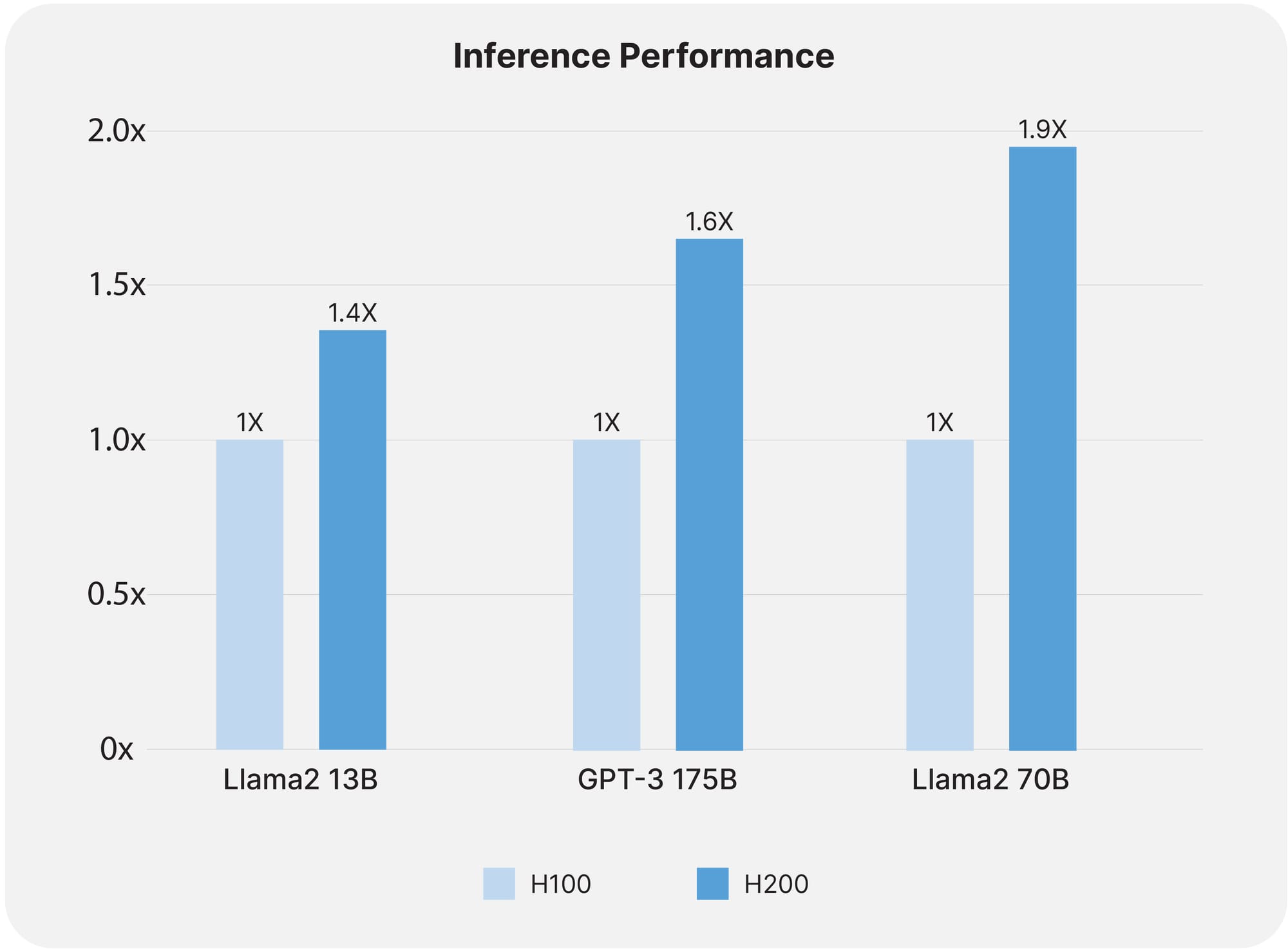
H200 Inference Performance
The NVIDIA H200 sets a new standard for AI inference, especially notable in its handling of large language models such as Llama2 70B. By doubling the inference performance relative to the H100, the H200 facilitates rapid processing and analysis, crucial for applications reliant on real-time data interpretation. This enhanced capability enables businesses to deploy more complex AI models efficiently, significantly improving response times and accuracy in AI-driven solutions.
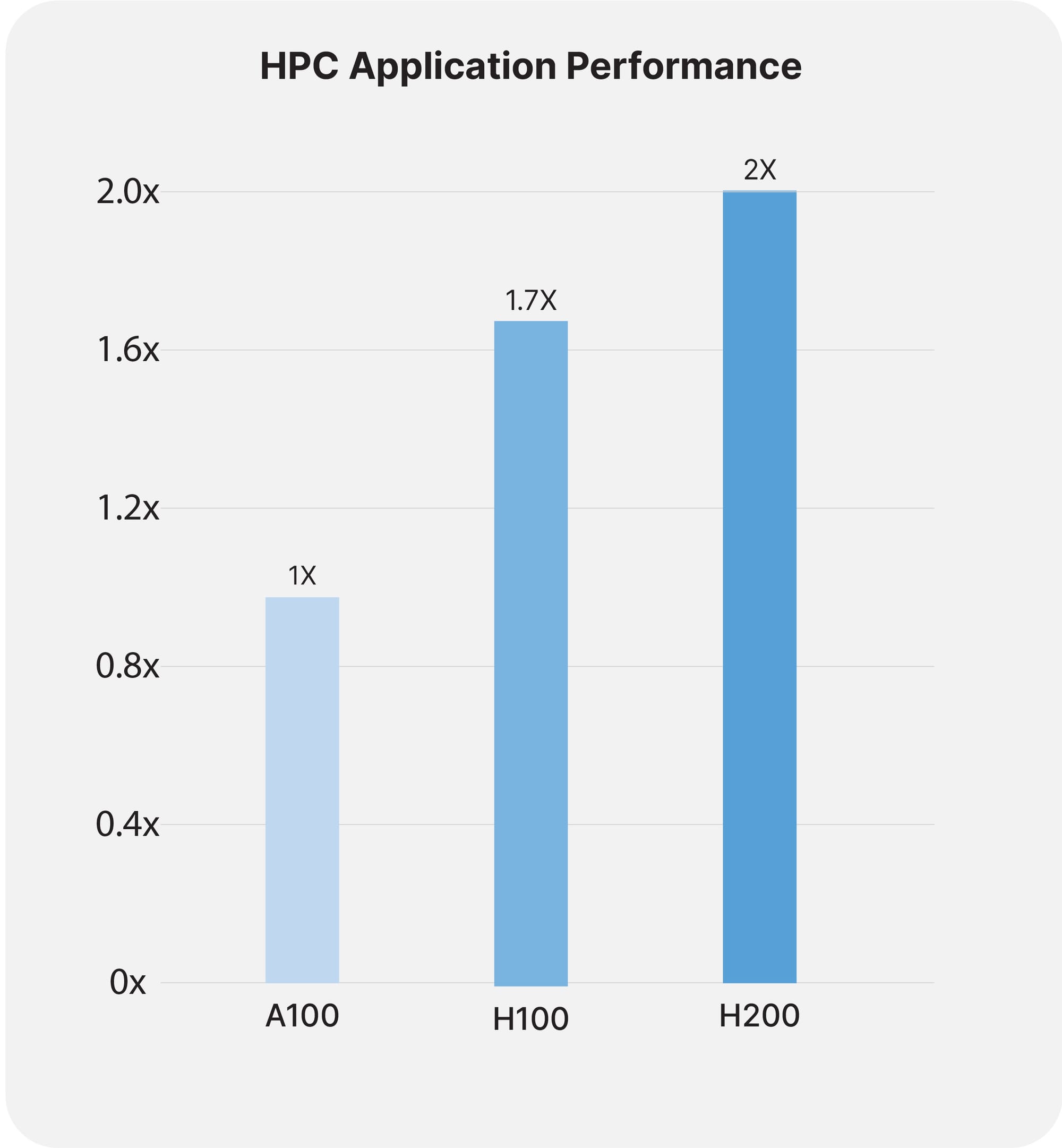
HPC Performance
In the domain of high-performance computing, the H200 distinguishes itself with substantial improvements in memory bandwidth and processing power. The GPU's architecture, equipped with 141GB of HBM3e memory and a bandwidth of 4.8TB/s, ensures unparalleled performance in memory-intensive HPC applications. These advancements lead to accelerated data transfer rates and reduced bottlenecks in complex computations, enabling researchers and engineers to achieve faster time-to-results in simulations, scientific research, and artificial intelligence tasks.
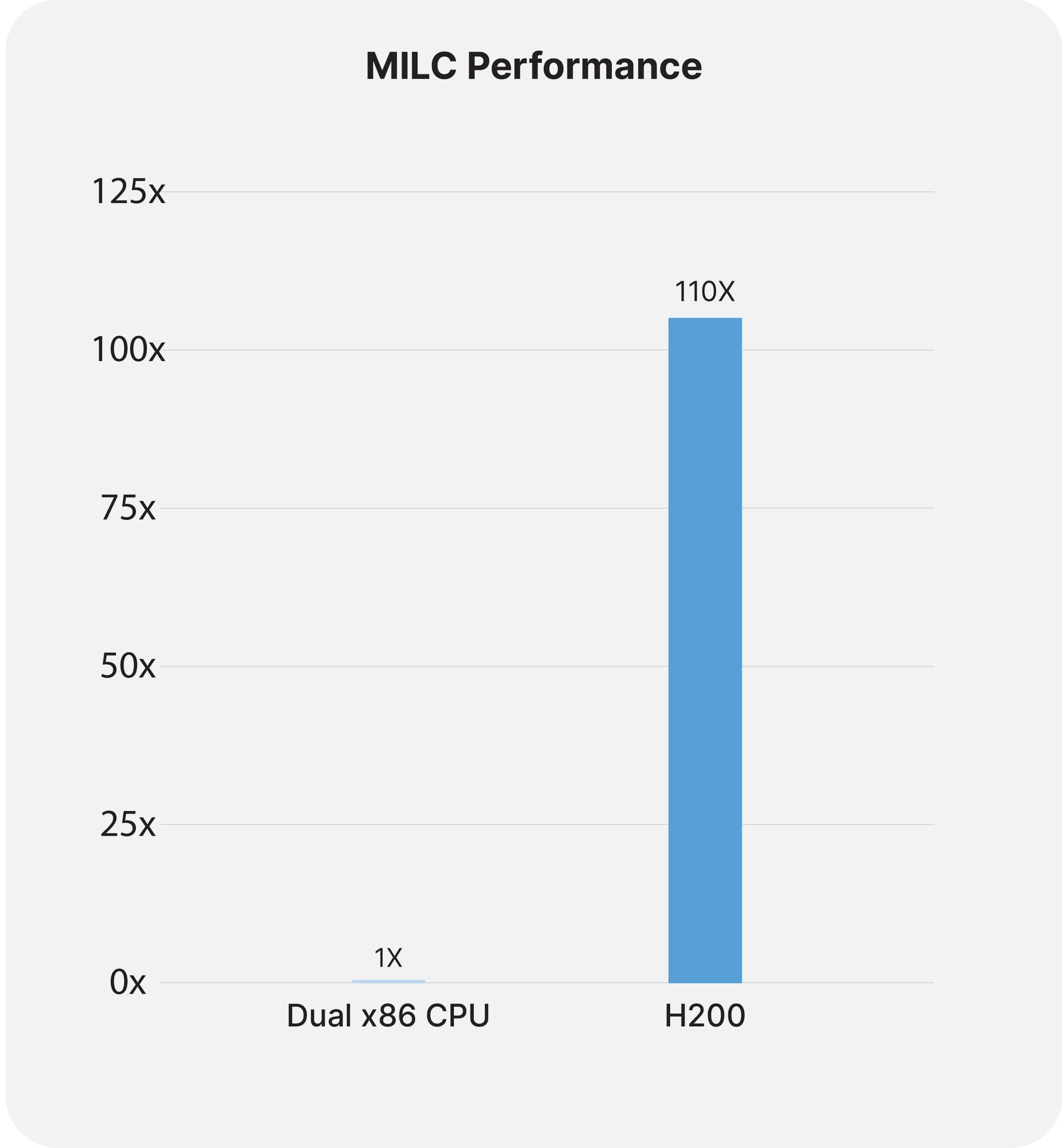
MILC Performance
For MIMD Lattice Computation (MILC), a critical component in quantum chromodynamics (QCD) simulations, the H200 GPU offers a remarkable performance boost. Leveraging its superior memory bandwidth and computational efficiency, the H200 significantly accelerates the processing of MILC datasets. This acceleration is vital for advancing our understanding of quantum phenomena and facilitating breakthroughs in particle physics research. The H200's capabilities ensure that data can be accessed and manipulated more efficiently, leading to an exponential increase in performance metrics compared to previous GPU generations, thus dramatically speeding up time to insight in this specialized field.
Future Use Cases
- Enabling advanced AI research and development
- Facilitating more complex and large-scale model training
- Driving breakthroughs in scientific computing and discoveries
NVIDIA H100 Overview
As NVIDIA's flagship for AI and HPC, the H100 GPU embodies the zenith of technology for accelerating AI models and managing large datasets, widely recognized in data centers and research domains.

The H100's advanced architecture and memory capabilities make it adept at navigating the complexities of AI and HPC challenges, offering significant computational and model training efficiencies.
Performance
Showcasing exceptional performance in AI training and inference, the H100 is instrumental in speeding up data processing and model iterations, essential for high-stake applications.
Use Cases
- Deep learning initiatives and projects
- Scientific simulations across various disciplines
- Large-scale AI deployments in enterprise and research environments
NVIDIA L40s Overview
Designed for professional visualization and AI inference, the NVIDIA L40S, with its Ada Lovelace architecture, stands as a versatile GPU for creative and design-oriented tasks.

The L40S excels in handling intensive graphic workloads and AI-driven applications, offering a potent mix of computational power and graphical performance suited to a broad spectrum of professional requirements.
Performance
Demonstrating efficiency in rendering and AI-driven design, the L40S's performance underscores its versatility and utility in applications requiring both graphical and computational prowess.
Use Cases
- Virtual design and immersive environments
- Content creation and multimedia projects
- Complex 3D modeling and animation
Specifications Comparison
| Feature | NVIDIA H100 SXM | NVIDIA L40S | NVIDIA H200 |
|---|---|---|---|
| Architecture & Cores | Hopper | NVIDIA Ada Lovelace, 18,176 CUDA Cores | Hopper |
| GPU Memory | 80GB | 48GB GDDR6 with ECC | 141GB |
| Memory Bandwidth | 3.35TB/s | 864GB/s | 4.8TB/s |
| Interconnect | NVLink 900GB/s, PCIe Gen5 128GB/s | PCIe Gen4 x16: 64GB/s bidirectional | NVLink 900GB/s, PCIe Gen5 128GB/s |
| Compute Performance (Various) | FP64: 34 TFLOPS FP64 Tensor Core: 67 TFLOPS FP32: 67 TFLOPS TF32 Tensor Core: 989 TFLOPS^2 BFLOAT16 Tensor Core: 1,979 TFLOPS^2 FP16 Tensor Core: 1,979 TFLOPS^2 FP8 Tensor Core: 3,958 TFLOPS^2 INT8 Tensor Core: 3,958 TOPS^2 |
RT Core: 209 TFLOPS FP32: 91.6 TFLOPS TF32 Tensor Core: 183 |
366* BFLOAT16 Tensor Core: 362.05 |
| Max TDP | Up to 700W (configurable) | 350W | Up to 700W (configurable) |
| Form Factor | SXM | 4.4" (H) x 10.5" (L), dual slot | SXM |
| Special Features | Multi-Instance GPUs up to 7 MIGs @ 10GB each, NVIDIA Enterprise Add-on included | Passive thermal, Virtual GPU Software Support, 3x NVENC | 3x NVDEC, Secure Boot with Root of Trust, NEBS Ready Level 3, No MIG or NVLink Support |
This comparison clarifies the distinct applications and strengths of the NVIDIA H200, H100, and L40S GPUs. From the revolutionary capabilities of the H200 in AI and HPC, the performance of the H100 in similar arenas, to the L40S's specialization in visualization and AI inference, AMAX integrates these GPUs to develop solutions that redefine the capabilities of IT infrastructure and AI applications.