
The escalating computational requirements in AI and high-performance computing (HPC), particularly for the new generation of trillion-parameter models, are prompting the development of multi-node, multi-GPU systems. These systems require efficient, high-speed communication among all GPUs. NVIDIA NVLink offers a key interconnect solution, enabling every GPU in the system to smoothly connect and communicate. NVLink's capability to directly connect multiple GPUs has enhanced performance across various applications, including supercomputing, AI, and machine learning. NVLink is essential in creating a scalable, comprehensive computing platform capable of keeping pace with today's complex business demands.

What is NVIDIA NVLink?
At its core, NVIDIA NVLink is a high-bandwidth, energy-efficient interconnect that enables direct communication between multiple GPUs. It eliminates traditional data bottlenecks and delivers significantly higher bandwidth and lower latency compared to conventional interconnects. This allows for smooth data sharing and parallel processing, resulting in superior performance and improved efficiency.

The Architecture of NVIDIA NVLink
NVLink is based on a point-to-point connection architecture, where each GPU is directly connected to every other GPU in the system. This direct connection allows for rapid data transfers and eliminates the need for the CPU to act as a middleman, reducing latency and maximizing performance.
Imagine a scenario where you have multiple GPUs working together to perform complex calculations for a scientific simulation. With NVLink, these GPUs can communicate with each other directly, without relying on the CPU to facilitate the exchange of data. This direct communication significantly reduces the time it takes for the GPUs to share information, resulting in faster and more efficient processing.
Additionally, the point-to-point connection architecture of NVLink ensures that each GPU has its own dedicated link to every other GPU in the system. This means that the bandwidth available for data transfers is not shared or divided among multiple GPUs, ensuring that each GPU can fully utilize the available bandwidth for maximum performance.
Key Features of NVIDIA NVLink
NVLink boasts several key features that make it a preferred choice for high-performance computing. First and foremost, it provides an extraordinary increase in bandwidth, allowing for faster data transfers and enabling GPUs to work cohesively as a single, powerful unit.
Imagine a scenario where you are training a deep learning model that requires massive amounts of data to be processed. With NVLink, the increased bandwidth allows for faster transfer of data between the GPUs, enabling them to process the data in parallel and accelerate the training process. This results in significant time savings and improved productivity.
In addition, NVLink supports peer-to-peer communication, meaning that GPUs can directly exchange data without CPU involvement, further reducing latency and enhancing performance. This feature is particularly beneficial in scenarios where multiple GPUs need to work together to process large datasets or perform complex simulations.
Furthermore, NVLink offers high energy efficiency, minimizing power consumption while delivering exceptional performance. The efficient design of NVLink ensures that the interconnect consumes less power compared to traditional interconnects, resulting in reduced energy costs and a smaller carbon footprint.
Moreover, NVLink's innovative design enables flexible configurations, allowing for various topologies, including mesh. In a mesh topology, each GPU is connected to multiple other GPUs, forming a network-like structure. This increases scalability and system resilience, as data can be routed through different paths in the network, ensuring that even if one link fails, the communication between GPUs can still continue through alternative routes.
NVIDIA NVLink technology revolutionizes the way GPUs communicate and work together in high-performance computing systems. Its high-bandwidth, energy-efficient interconnect enhances data sharing, parallel processing, and overall system performance. With its innovative architecture and key features, NVLink provides a powerful solution for accelerating scientific simulations, deep learning, and other computationally intensive tasks.

How NVLink works with NVSwitch
NVLink and NVSwitch work together to enhance GPU communication in high-performance computing systems. NVLink provides direct, high-speed connections between GPUs within a server, significantly boosting data transfer rates. NVSwitch expands on this by interconnecting multiple NVLinks, enabling efficient, all-to-all communication across GPUs both within and between servers, thus creating a more cohesive and powerful computing network.
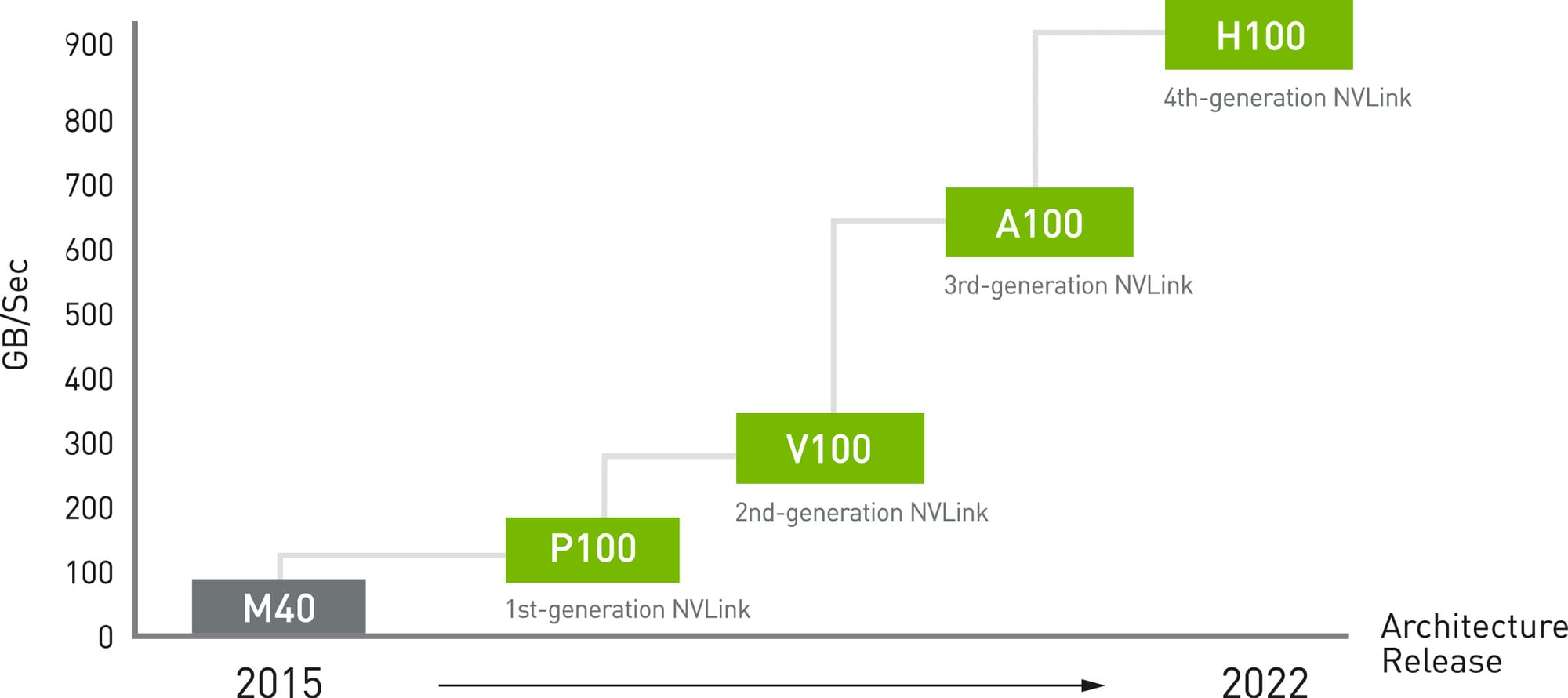
NVLink, now in its fourth generation, is NVIDIA's answer to the increasing demands for high-speed, direct GPU-to-GPU interconnects within servers. This technology has taken a significant leap forward, offering 1.5 times higher bandwidth compared to its previous iteration. A standout feature is the capability of a single NVIDIA H100 Tensor Core GPU to support up to 18 NVLink connections, providing a total bandwidth of 900 GB/s. This is a substantial improvement over the bandwidth offered by PCIe Gen5, making NVLink a cornerstone technology for deep learning and advanced computational tasks.
Building on the foundation laid by NVLink, NVSwitch expands these capabilities to a new level. The third-generation NVSwitch is equipped with 64 NVLink ports and incorporates the NVIDIA Scalable Hierarchical Aggregation Reduction Protocol (SHARP)™. This innovation enables high-speed, all-to-all GPU communication, both within a single node and across multiple nodes. The result is a seamless, high-bandwidth, multi-node GPU cluster that is essential for tackling the most demanding compute tasks in AI and HPC.
The Combined Power of NVLink and NVSwitch
When NVLink and NVSwitch are used in tandem, they create a robust and scalable multi-GPU environment. This synergy is not just about enhancing GPU-to-GPU communication within a server; it's about creating a cohesive, powerful system that can handle the complexities of trillion-parameter models and other intensive computational workloads. The potential for future systems is even more impressive, with the ability to connect up to 256 GPUs and deliver an astonishing 57.6 TB/s of all-to-all bandwidth.
The Impact on AI and HPC
The integration of NVLink and NVSwitch is a game-changer for AI and HPC applications. These technologies are essential components of NVIDIA's comprehensive data center solution, which includes hardware, networking, software, and optimized AI models. They enable researchers and professionals to push the boundaries of what's possible, delivering real-world results and deploying solutions that drive unprecedented acceleration at every scale.

The Role of NVLink in High-Performance Computing
Supercomputing has always demanded innovative technologies to push the boundaries of what is possible. NVLink has shown to be a critical component in connecting supercomputing clusters, enabling massive compute power and accelerated performance for scientific research, simulations, and data-intensive applications.
When it comes to supercomputing, NVLink has revolutionized the way researchers and scientists tackle complex problems. The ability to harness the power of NVLink has truly pushed the boundaries of scientific research, allowing for new discoveries and advancements.
NVLink in Supercomputing
In the realm of supercomputing, NVLink has enabled researchers and scientists to tackle complex problems with unprecedented speed. By connecting multiple GPUs, NVLink enables massive parallel processing, significantly accelerating computationally demanding tasks. Whether it is modeling climate change, simulating particle physics, or optimizing drug discovery, NVLink plays a vital role in pushing the boundaries of scientific research.
Imagine a world where scientists can simulate the behavior of millions of particles in real-time, allowing for a deeper understanding of the fundamental forces that shape our universe. Thanks to NVLink, this world is now a reality. With its high-bandwidth and low-latency architecture, NVLink empowers supercomputers to process vast amounts of data quickly and efficiently. This means that scientists can now run simulations that were once thought impossible, leading to breakthroughs in fields such as astrophysics, material science, and bioinformatics.
NVLink in AI and Machine Learning
AI and machine learning are revolutionizing industries across the globe, from healthcare to finance to autonomous vehicles. NVLink's high-bandwidth and low-latency architecture empowers AI engineers and data scientists to train and deploy complex neural networks at an unprecedented scale. Whether it is natural language processing, image recognition, or reinforcement learning, NVLink provides the performance required to process vast amounts of data quickly and efficiently.
Imagine a world where self-driving cars can navigate complex road conditions with ease, thanks to AI algorithms trained on massive amounts of real-world data. NVLink makes this world possible by enabling the training of deep neural networks at an unprecedented scale. With its high-bandwidth connections between GPUs, NVLink allows for the instant sharing of data, enabling faster training times and more accurate models. This has significant implications not only for autonomous vehicles but also for other AI applications such as healthcare diagnosis, fraud detection, and personalized recommendations.
NVLink has become an indispensable technology in the world of high-performance computing. Its ability to connect multiple GPUs and provide high-bandwidth, low-latency communication has revolutionized scientific research, supercomputing, and AI applications. With NVLink, researchers and scientists can push the boundaries of what is possible, enabling new found discoveries and advancements in various fields. As technology continues to evolve, NVLink will undoubtedly play an even more significant role in shaping the future of high-performance computing.
Comparing NVLink with Other Interconnect Technologies
While NVLink has proven its worth in the world of high-performance computing, it is essential to understand how it stacks up against other interconnect technologies.
Interconnect technologies play a crucial role in enabling efficient communication between components in a computing system. Let's dive deeper into the comparisons between NVLink and two other popular interconnect technologies: PCI Express (PCIe) and AMD's Infinity Fabric.

NVLink vs PCI Express
When comparing NVLink with the widely used PCI Express (PCIe) interface, the advantages of NVLink become apparent. PCIe, originally designed for peripheral devices, has limited bandwidth and higher latency compared to NVLink.
PCIe, with its shared bus architecture, can introduce bottlenecks when multiple devices are communicating simultaneously. This limitation can hinder the performance of GPUs, especially in high-performance computing scenarios where data transfer speed is crucial.
In contrast, NVLink's point-to-point topology and high-speed connections enable GPUs to communicate easily without the bottlenecks often associated with PCIe. With NVLink, GPUs can establish direct connections, allowing for faster data transfers and reduced latency. This direct communication path between GPUs enhances overall system performance, making NVLink a preferred choice for demanding computational workloads.

NVLink vs Infinity Fabric
Another notable interconnect technology is AMD's Infinity Fabric. Designed to connect multiple CPUs and GPUs, Infinity Fabric aims to provide high-speed communication between these components.
However, when comparing NVLink with Infinity Fabric, NVLink emerges as the superior choice for high-performance computing. NVLink provides higher bandwidth and lower latency, making it more suitable for data-intensive workloads.
One of the key advantages of NVLink is its ability to establish direct connections between GPUs. This direct connection eliminates the need for intermediate components, reducing latency and enhancing overall system performance. In contrast, Infinity Fabric, while efficient in connecting CPUs and GPUs, may introduce additional latency due to its more complex routing architecture.
Furthermore, NVLink's superior bandwidth allows for faster data transfers between GPUs, enabling efficient parallel processing. This capability is particularly beneficial in multi-GPU configurations, where NVLink's scalability and performance shine.
NVLink stands out as a robust interconnect technology for high-performance computing. Its point-to-point topology, high-speed connections, and direct GPU-to-GPU communication offer superior performance and scalability compared to PCIe and Infinity Fabric. As the demand for computational power continues to grow, NVLink's capabilities make it an ideal choice for accelerating scientific research, deep learning, and other computationally intensive tasks.

Upcoming Developments in NVLink
NVIDIA is committed to pushing the boundaries of GPU technology, and NVLink is poised for significant advancements. The newest GPUs from NVIDIA such as the H200 and GH200 super chip are utilizing NVLink as well for highspeed interconnect. Future developments may include increased bandwidth, improved power efficiency, and enhanced compatibility with emerging GPU architectures. These developments will further enhance the performance and capabilities of NVLink, propelling high-performance computing to new heights.
The Impact of NVLink on Future Technologies
NVLink's impact extends beyond the realms of high-performance computing. As AI and machine learning become increasingly central to our everyday lives, NVLink will continue to enable breakthroughs in autonomous vehicles, personalized medicine, and advanced robotics. The power and efficiency of NVLink pave the way for a future where technology enhances our lives in ways we have yet to imagine.

Maximizing Performance with NVLink
To fully harness the power of NVIDIA NVLink, it is crucial to adopt best practices and address any potential challenges.
Best Practices for Using NVLink
When leveraging NVLink, it is essential to design applications and algorithms that exploit its high-bandwidth capabilities. This involves optimizing data transfer techniques, utilizing parallel processing effectively, and ensuring proper load balance across GPUs. Developers should also consider NVLink's memory capabilities, as it allows GPUs to access each other's memory directly, opening avenues for more efficient and scalable algorithms.
Troubleshooting Common NVLink Issues
While NVLink offers unrivaled performance, occasional issues may arise. It is vital to stay informed about potential compatibility issues, ensure proper cooling and power supply for GPUs, and keep drivers up-to-date. NVIDIA's support resources and community forums can provide valuable guidance and troubleshooting tips to overcome any challenges.
NVIDIA NVLink has proven to be a game-changer in the world of high-performance computing and advanced technologies. Its exceptional speed, scalability, and energy efficiency have unlocked a new era of performance, enabling breakthroughs in scientific research, AI, and machine learning. As this remarkable technology continues to evolve and impact future technologies, the possibilities are endless.